LoTIS: Learning to Localize Reference Trajectories in Image-Space for Visual Navigation
TL;DR: Given a video recorded with e.g. your phone, LoTIS enables your robot to navigate to any point on the recorded trajectory, from any view of it, using only an on-board RGB camera, without any further training.
Abstract
We present LoTIS, a model for visual navigation that provides robot-agnostic image-space guidance by localizing a reference RGB trajectory in the robot's current view, without requiring camera calibration, poses, or robot-specific training. Instead of predicting actions tied to specific robots, we predict the image-space coordinates of the reference trajectory as they would appear in the robot's current view. This creates robot-agnostic visual guidance that easily integrates with local planning. Consequently, our model's predictions provide guidance zero-shot across diverse embodiments. By decoupling perception from action and learning to localize trajectory points rather than imitate behavioral priors, we enable a cross-trajectory training strategy that learns robust invariance to viewpoint and camera changes. We outperform state-of-the-art methods by 20-50 percentage points in success rate on forward navigation, and paired with a local planner we achieve 94-98% success rate across diverse sim and real environments. Furthermore, we achieve over 5x improvements on challenging tasks where baselines fail, such as backward traversal. The system is straightforward to use: we show how even a video from a handheld phone camera directly enables different robots to navigate to any point on the trajectory.
Method
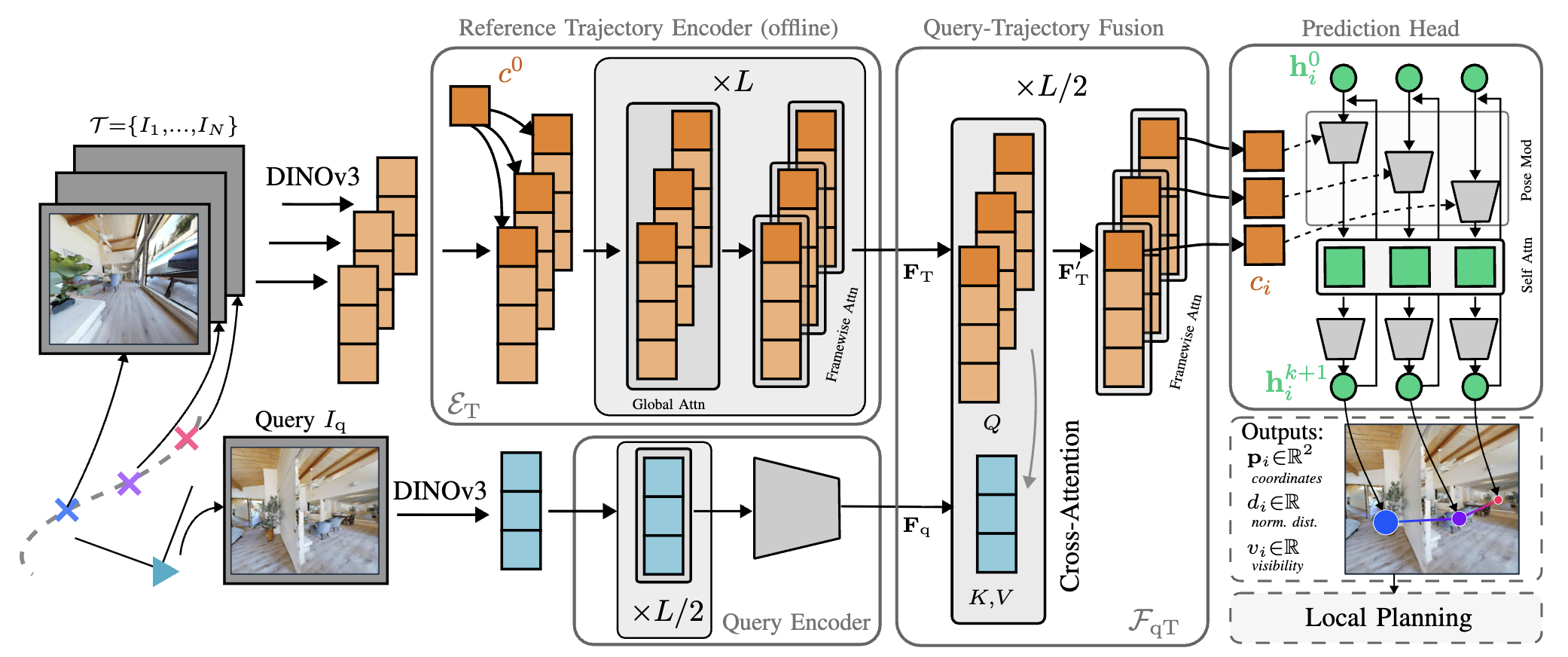
LoTIS decouples perception from action by predicting where a reference trajectory appears in the robot's current view, rather than predicting robot-specific actions. For each frame in the reference trajectory, our model outputs: (1) the 2D image coordinates where that pose would appear, (2) whether it's visible, and (3) its normalized distance. This robot-agnostic representation interfaces directly with any local planner, enabling zero-shot transfer across embodiments, from drones to quadrupeds, using the same phone-recorded trajectory. A cross-trajectory training strategy, where reference and query images come from different trajectories, teaches robustness to camera mismatch and enables backward traversal where prior methods fail.
Experiment Gallery
Reference trajectories recorded with a handheld phone. Navigation runs start from arbitrary positions with visual overlap to the reference.
Reference Trajectory
Forward Navigation
Navigate to the end of the trajectory. The robot must match visual features despite viewpoint and camera differences from the handheld reference.
Start 0
Start 1
Start 2
Start 3
Start 4
Start 5
Backward Navigation
Return to the start of the trajectory. This is significantly harder: the robot sees the opposite viewpoint from the reference, so methods relying on visual similarity fail. You can explore an example of the model inferences on backwards views in our demo.
Start 0
Start 1
Start 2
Start 3
Start 4
Start 5
Robustness Experiments
LoTIS maintains strong performance under challenging real-world conditions.
Using the same Indoors 2 reference trajectory (recorded without people), but now people walk through the scene during navigation, occluding the robot's view.
Forward Navigation
Start 0
Start 1
Start 2
Start 3
Start 4
Start 5
Backward Navigation
Start 0
Start 1
Start 2
Start 3
Start 4
Start 5
Kilometer-Scale Navigation
LoTIS scales to long-range outdoor trajectories.
BibTeX
@misc{busch2026learninglocalizereferencetrajectories,
title={Learning to Localize Reference Trajectories in Image-Space for Visual Navigation},
author={Finn Lukas Busch and Matti Vahs and Quantao Yang and Jesús Gerardo Ortega Peimbert and Yixi Cai and Jana Tumova and Olov Andersson},
year={2026},
eprint={2602.18803},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2602.18803},
}